In this post, we will dive into the Selenium Webdriver Find Element API. Webdriver has two levels of interrogation which as we can refer to as finding something on the browser page, these are WebDriver and DOM level interrogations. I will explain and show examples of both levels of finding anything on the browser.
WebDriver Level Find in Selenium (Selenium Versions: 2, 3, 4)
Webdriver level find consists of below functions:
. getTitle() – returns page title as String
.getCurrentUrl() – returns current URL as String
.getPageSource() – returns page source as String (Note: Webdriver returns some page source differences depends on a driver of browsers. But if you check a text, this will not be a problem. All drivers of browsers return the content of the page correctly.)
Webdriver Level Find Examples
import static org.hamcrest.CoreMatchers.is;
import static org.hamcrest.MatcherAssert.assertThat;
import org.junit.jupiter.api.AfterAll;
import org.junit.jupiter.api.Assertions;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.TestInstance;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
@TestInstance(TestInstance.Lifecycle.PER_CLASS)
public class DriverLevelFind {
private WebDriver driver;
final private String URL = "https:";
@BeforeAll
public void setupTest() {
driver = new ChromeDriver();
}
@BeforeEach
public void navigateToSwTestAcademy() {
//Go to www.firebrick-termite-918071.hostingersite.com
driver.navigate().to(URL);
}
//.getTitle Example
@Test
public void T01_getTitle() {
//Check title
assertThat(driver.getTitle(), is("Software Test Academy"));
}
//.getCurrentURL Example
@Test
public void T02_getCurrentURL() {
//Check Current URL
assertThat(driver.getCurrentUrl(), is("https:/"));
}
//.getPageSource Example
@Test
public void T03_getPageSource() {
//Get PageSource and save it into a String
String pageSource = driver.getPageSource();
//Check page source contains ""
Assertions.assertTrue((pageSource.contains("swtestacademy")));
}
@AfterAll
public void quitDriver() {
driver.quit();
}
}Find Elements with Relative Locators in Selenium 4
In selenium 4, a new locator approach has been announced as Relative Locators. For this, I wrote a comprehensive article and you can find it here.
Find Elements in Selenium (Versions: 2, 3, 4)
First of all, we have to start with what is DOM. DOM expansion is Document Object Model. The Document Object Model is a programming API for HTML and XML documents. It defines the logical structure of HTML and the way a page is accessed and manipulated.
DOM Example:
<TABLE> <ROWS> <TR> <TD>Jack</TD> <TD>Mike</TD> </TR> <TR> <TD>Jason</TD> <TD>Celine</TD> </TR> </ROWS> </TABLE>

* For more information you can visit http://www.w3.org/TR/WD-DOM/introduction.html
Everything in a web page such as text box, button, paragraph, etc. is a web element in webdriver. We can interrogate web elements via WebDriver’s interrogation methods such as .getText(), isSelected(), .getSize(), .getLocation(), etc. Finding elements can be done in two steps. First, we have to find the element which we want to interrogate, and then we can interrogate it with WebDriver’s interrogation methods. For example, if we want to get the text of Google’s “Gmail” link:


1) We have to find the element via id, CSS, or XPath selectors. In this example I used Xpath.
(Note: Selectors will be described later posts so now just see their usage. You can find elements also with some extensions like Ranorex Selocity, SelectorsHub, ChroPath, etc.)
WebElement gmailLink = driver.findElement(By.xpath("//*[contains(@href,'https://mail.google.com/mail/')]"));For this kind of smart Xpath locator tactics, you can read my article on XPath locators.
2) Get Gmail link’s text via .getText() method.
assertThat(gmailLink.getText(), is("Gmail"));Finding Elements with By Methods
Webdriver’s find methods with “By” are listed below.
| Method | Syntax | Description |
| By.id | driver.findElement(By.id(<element ID>)) | Locates an element using the ID attribute. |
| By.name | driver.findElement(By.name(<element name>)) | Locates an element using the Name attribute |
| By.LinkText | driver.findElement(By.linkText(<linktext>)) | Locates a link using link text |
| By.partialLinkText | driver.findElement(By.partialLinkText(<linktext>)) | Locates a link using the link’s partial text |
| By.className | driver.findElement(By.className(<element class>)) | Locates an element using the Class attribute |
| By.tagName | driver.findElement(By.tagName(<htmltagname>)) | Locates an element using the HTML tag |
Selenium Find By Id
http://the-internet.herokuapp.com/ is our test site
Navigate to http://the-internet.herokuapp.com/login
Then we will right-click inspect on chrome to see the HTML source. Here I suggest some chrome extensions like Ranorex Selocity, ChroPath, and SelectorsHub. By using these extensions, you can get the CSS and XPath locators easier. I will show these three, extensions now. :)
On the login page, I clicked the username field and now let’s see what these tools can give us one by one.

Ranorex Selocity

ChroPath

SelectorsHub
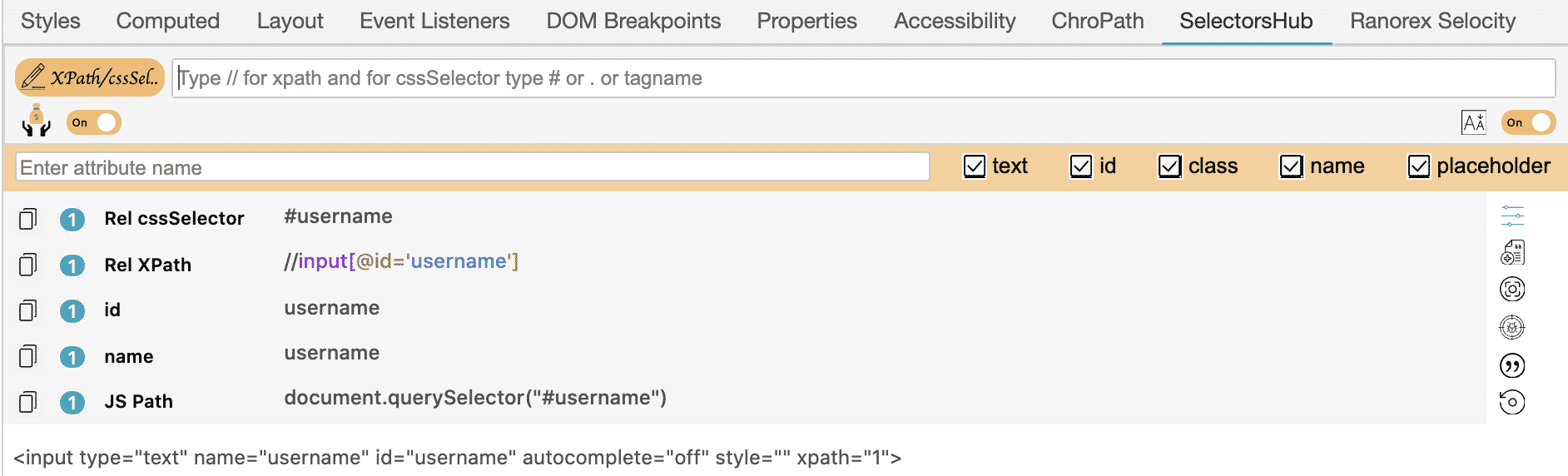
You can use any of them as your decision but whichever your will use know the best practices in CSS and XPath locators.
Let’s continue :) In the below picture, the attribute of the username field is “username”.

Test code is shown below:
@Test
public void T01_findById() {
//Find user name text box by By.id method
WebElement userName = driver.findElement(By.id("username"));
//Assert that text box is empty
Assertions.assertEquals("", userName.getText());
}Selenium Find By Name
This time we can find the username by using its name attribute.
Test code is shown below:
@Test
public void T02_findByName() {
//Find user name text box by By.Name method
WebElement userName = driver.findElement(By.name("username"));
//Assert that text box is empty
Assertions.assertEquals("", userName.getText());
}Selenium Find By LinkText
This time we can find the Elemental Selenium text by using linkText method.
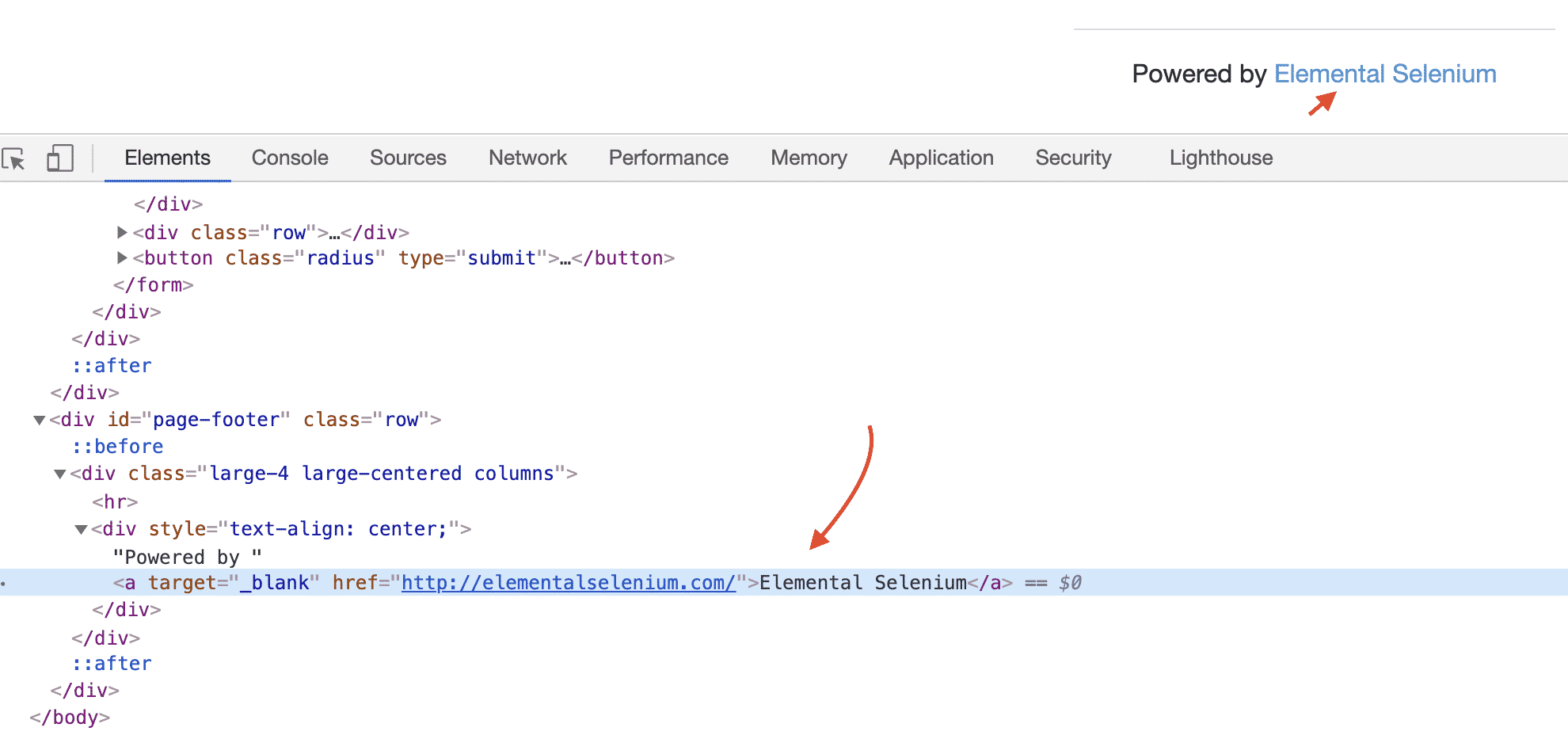
@Test
public void T03_findLinkText() {
driver.navigate().to(baseURL + "/login");
//Find text by By.LinkText method
WebElement link = driver.findElement(By.linkText("Elemental Selenium"));
//Assert that text box is empty
Assertions.assertEquals("Elemental Selenium", link.getText());
}Selenium Find By PartialLinkText
With this method, we can locate the link with its partial text.
@Test
public void T04_findPartialLinkText() {
//Find text by By.partialLinkText method
WebElement link = driver.findElement(By.partialLinkText("Elemental Sel"));
//Assert that text box is empty
Assertions.assertEquals("Elemental Selenium", link.getText());
}Selenium Find By ClassName
We can access any object with its class name. In the below example, we will find the subheader by using the By.className method, and then we will verify it via contains assertion.
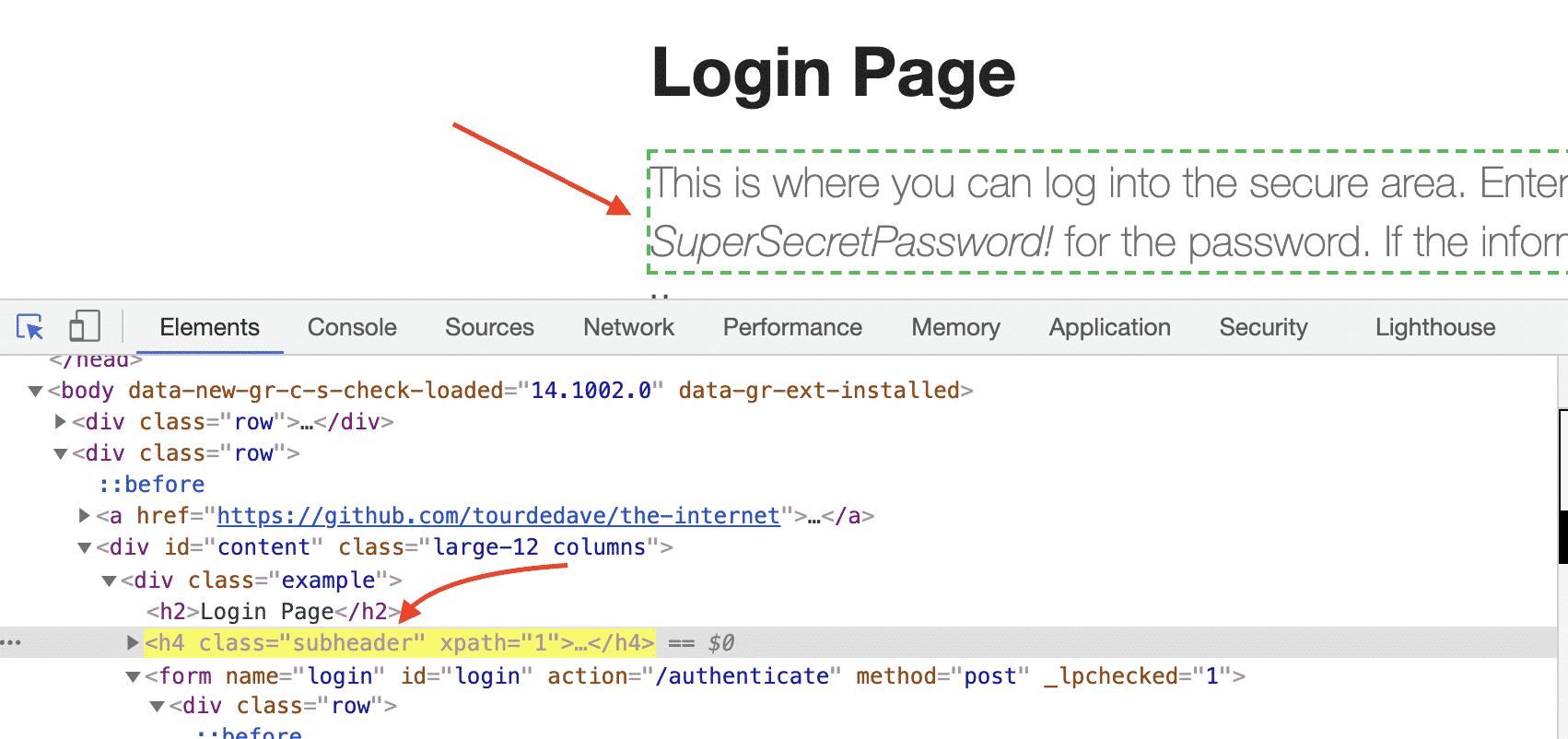
@Test
public void T05_findClassName() {
//Find subheader by using By.className
WebElement subHeader = driver.findElement(By.className("subheader"));
//Assert that subheader contains SuperSecretPassword
Assertions.assertTrue(subHeader.getText().contains("SuperSecretPassword"));
}Selenium Find By TagName
In our sample page, we have two input fields these are username and password. Let’s find them all with their tag name “input” and verify that we have two input fields.
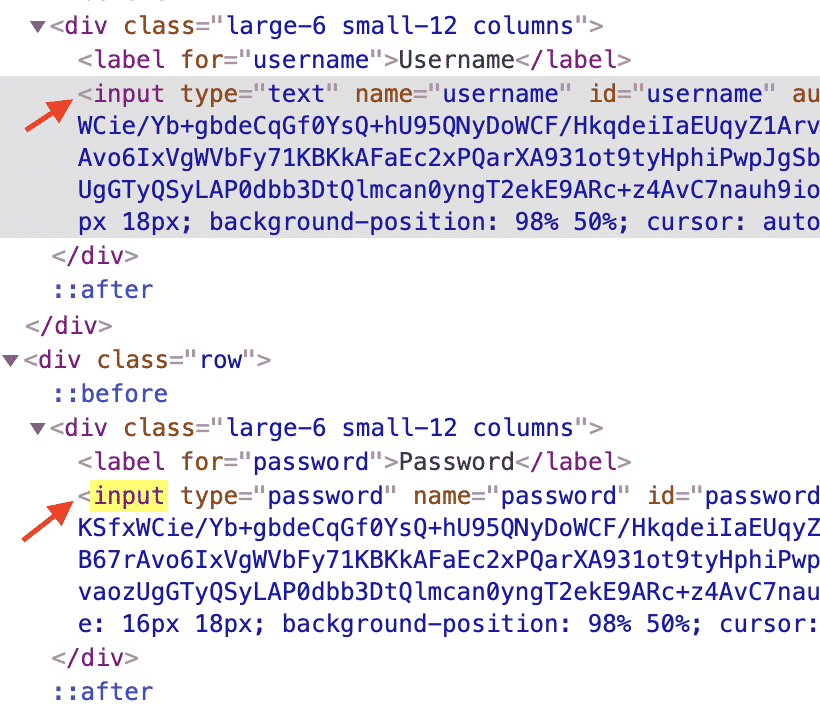
@Test
public void T06_findTagName() {
//Find input fields by By.tagName method
List<WebElement> inputTags = driver.findElements(By.tagName("input"));
//Assert that text box is empty
Assertions.assertEquals(2, inputTags.size());
}Chaining with findElements Methods and ByChained Support Class
The below example is created by using the old Linkedin Homepage but now it has been changed but the main idea of this method is the same and you can apply it on any page.
In any web page, there is more than one web element that has got the same id, name, class, etc. We can interrogate any web element by chaining its id, name, tag name, etc. and we can do that in two ways:
- Chaining with findElement by methods
- Chaining with ByChained support class
You can find these two ways in the below examples.
Again our test site is linkedin.com main page :)
As you can see in the picture there are several links on the main page under “div class=link” and our aim to locate “About” link.
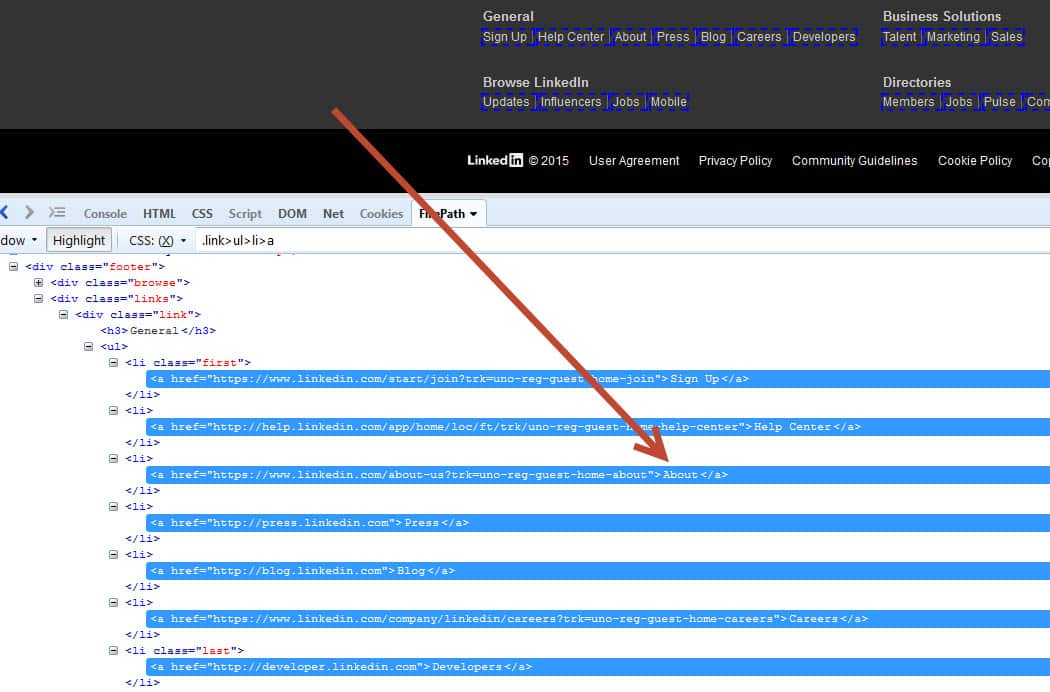
To locate the “About” link, first, we will chain findElement methods which are shown in the below example.
@Test
public void T07_chainingWithFindElementMethods(){
//Navigate to Linkedin.com
driver.navigate().to("https://www.linkedin.com/");
WebElement element = driver.findElement(By.className("link")).
findElement(By.linkText("About"));
assertThat(element.getAttribute("href"), is("https://www.linkedin.com/about-us?trk=uno-reg-guest-home-about"));
}
and the second way is using ByChained support class.
@Test
public void T08_chainingWithByChained(){
//Navigate to Linkedin.com
driver.navigate().to("https://www.linkedin.com/");
WebElement element;
element = driver.findElement(
new ByChained(
By.className("link"),
By.linkText("About")));
assertThat(element.getAttribute("href"), is("https://www.linkedin.com/about-us?trk=uno-reg-guest-home-about"));
}
Finding Elements by CSS Selectors
First of all CSS selectors are faster. Yes, it is faster and more flexible than XPath selectors. Thus, it should be your default way to interrogate the web elements.
You can learn how to write effective CSS locators in this article.
We can find an element’s CSS path very easily with the Ranorex Selocity addon. Its installation is described in RanorexSelocity post. (Also, you can use ChroPath, and SelectorsHub).
Below the CSS of the subheader is so easy. We can find its class name and in CSS we are locating class names by using (.) operator so the CSS locator of the subheader will be “.subheader”.
This test’s code is shown below:
@Test
public void T07_findCSS() {
//Find subheader by using By.className
WebElement subHeader = driver.findElement(By.cssSelector(".subheader"));
//Assert that subheader contains SuperSecretPassword
Assertions.assertTrue(subHeader.getText().contains("SuperSecretPassword"));
}Finding Elements by XPath Selectors
XPath is generally slower than CSS. It is better to use CSS rather than XPath but if you really get in trouble by interrogation with CSS then at that time you can use XPath. I do not want to go into detail about all XPath here but you can find all tactics of XPath selectors here.
In our codes, we use “By.xpath” syntax to interrogate XPath selectors. Lets, find the subheader this time by using XPath locators.
This is the test code:
@Test
public void T07_findXPath() {
//Find subheader by using By.className
WebElement subHeader = driver.findElement(By.xpath("//h4[@class='subheader']"));
//Assert that subheader contains SuperSecretPassword
Assertions.assertTrue(subHeader.getText().contains("SuperSecretPassword"));
}
GitHub Project
https://github.com/swtestacademy/selenium-examples/tree/main/src/test/java/findelement
CSS & XPath Reference:
In the below reference all the properties and functions of XPath, CSS, DOM are written side by side. I highly recommend this reference and also you can download this reference as a PDF from the below link.
https://www.simple-talk.com/dotnet/.net-framework/xpath,-css,-dom-and-selenium-the-rosetta-stone/
Thanks,
Onur Baskirt

Onur Baskirt is a Software Engineering Leader with international experience in world-class companies. Now, he is a Software Engineering Lead at Emirates Airlines in Dubai.
many thanks for your extremely cool and clear articles!
You are welcome Alexey. I will continue to write new ones. Please, stay tuned ;)
Well Draftet, Onur!
Love to see all articles related to Selenium Webdrivers. All of them were written with full of maturity & making sure that audience will improve there technical level.
Love to see more articles of yours,
Regards,
Kumar Gaurav | India
Thank you Kumar. I will try to put more content to the site.